Ishigami Function#
import numpy as np
import matplotlib.pyplot as plt
import uqtestfuns as uqtf
The Ishigami test function is a three-dimensional scalar-valued function. First introduced in [IH91] in the context of sensitivity analysis, the function has been revisited many times in the same context (see for instances [SobolL99, Sud08, MILR09]).
Test function instance#
To create a default instance of the Ishigami test function:
my_testfun = uqtf.Ishigami()
Check if it has been correctly instantiated:
print(my_testfun)
Function ID : Ishigami
Input Dimension : 3 (fixed)
Output Dimension : 1
Parameterized : True
Description : Ishigami function from Ishigami and Homma (1991)
Applications : sensitivity
Description#
The Ishigami function, a highly non-linear and non-monotonic function, is given as follows:
where \(\boldsymbol{x} = \{ x_1, x_2, x_3 \}\) is the three-dimensional vector of input variables further defined below, and \(\boldsymbol{p} = \{ a, b \}\) are the parameters of the function.
Probabilistic input#
Based on [IH91], the probabilistic input model for the Ishigami function consists of three independent uniform random variables with the ranges shown in the table below.
Function ID : Ishigami
Input ID : Ishigami1991
Input Dimension : 3
Description : Probabilistic input model for the Ishigami function from
Ishigami and Homma (1991).
Marginals :
No. Name Distribution Parameters Description
----- ------ -------------- ------------------------- -------------
1 X1 uniform [-3.14159265 3.14159265] -
2 X2 uniform [-3.14159265 3.14159265] -
3 X3 uniform [-3.14159265 3.14159265] -
Copulas : Independence
Parameters#
The parameters of the Ishigami function are two real-valued numbers. Some of the available parameter values taken from the literature are shown in the table below.
No. |
Value |
Keyword |
Source |
|---|---|---|---|
1 |
\(a = 7\), \(b = 0.1\) |
|
[IH91] |
2 |
\(a = 7\), \(b = 0.05\) |
|
[SobolL99] |
Function ID : Ishigami
Parameter ID : Ishigami1991
Description : Parameter set for the Ishigami function from Ishigami and
Homma (1991)
No. Keyword Value Type Description
----- --------- ----------- ------ -------------
1 a 7.00000e+00 float
2 b 1.00000e-01 float
Note
To use another set of parameters, create a default test function
and pass one of the available keywords
(as indicated in the table above) to the parameters_id parameter.
For example:
my_testfun = uqtf.Ishigami(parameters_id="Sobol1999")
Reference results#
This section provides several reference results of typical UQ analyses involving the test function.
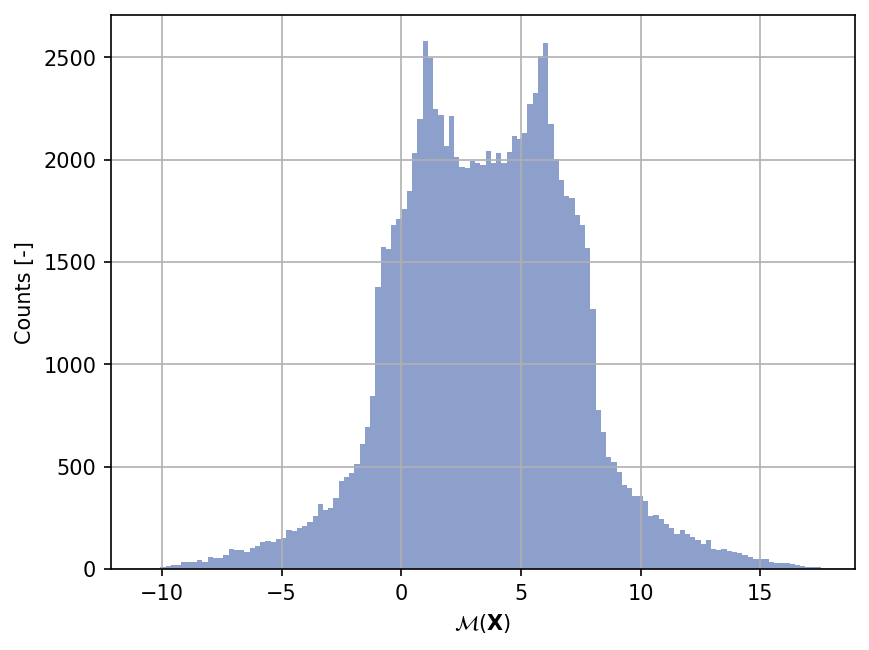
Sample histogram#
Shown below is the histogram of the output based on \(100'000\) random points:
Moment estimations#
The mean and variance of the Ishigami function can be computed analytically,
and the results are:
\(\mathbb{E}[Y] = \frac{a}{2}\)
\(\mathbb{V}[Y] = \frac{a^2}{8} + \frac{b \pi^4}{5} + \frac{b^2 \pi^8}{18} + \frac{1}{2}\)
Notice that the values of these two moments depend on the choice of the parameter values.
Shown below is the convergence of a direct Monte-Carlo estimation of the output mean and variance with increasing sample sizes compared with the analytical values.
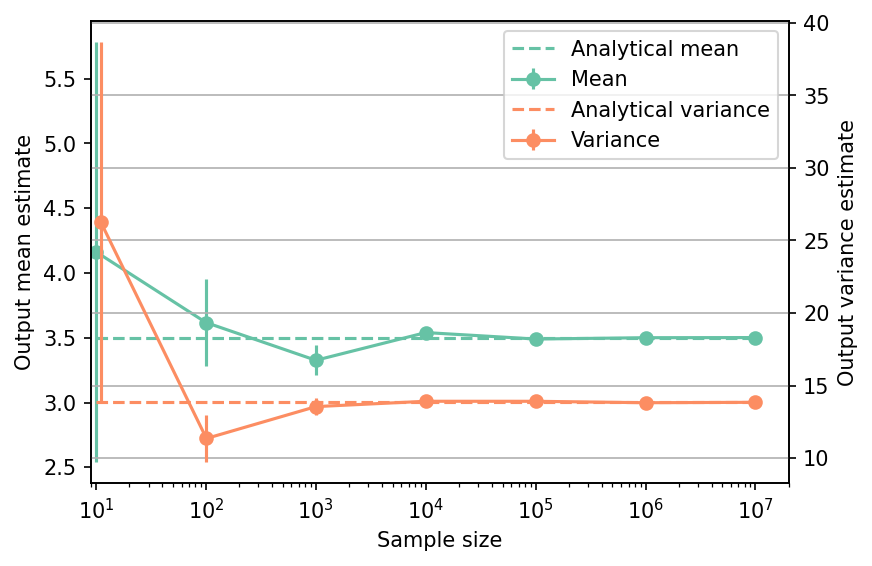
The tabulated results for each sample size is shown below.
| Sample size | Mean | Mean error | Variance | Variance error | Remark |
|---|---|---|---|---|---|
| nan | 3.5000e+00 | 0.0000e+00 | 1.3845e+01 | 0.0000e+00 | Analytical |
| 1.0e+01 | 4.1631e+00 | 1.6215e+00 | 2.6293e+01 | 1.2394e+01 | Monte-Carlo |
| 1.0e+02 | 3.6177e+00 | 3.3700e-01 | 1.1357e+01 | 1.6142e+00 | Monte-Carlo |
| 1.0e+03 | 3.3260e+00 | 1.1641e-01 | 1.3552e+01 | 6.0637e-01 | Monte-Carlo |
| 1.0e+04 | 3.5400e+00 | 3.7309e-02 | 1.3920e+01 | 1.9686e-01 | Monte-Carlo |
| 1.0e+05 | 3.4901e+00 | 1.1798e-02 | 1.3918e+01 | 6.2245e-02 | Monte-Carlo |
| 1.0e+06 | 3.5004e+00 | 3.7174e-03 | 1.3819e+01 | 1.9544e-02 | Monte-Carlo |
| 1.0e+07 | 3.5015e+00 | 1.1768e-03 | 1.3848e+01 | 6.1931e-03 | Monte-Carlo |
Sensitivity indices#
The main-effect and total-effect Sobol’ indices of the Ishigami function can be
derived analytically.
The main-effect (i.e., first-order) Sobol’ indices are:
\(S_1 \equiv \frac{V_1}{\mathbb{V}[Y]}\)
\(S_2 \equiv \frac{V_2}{\mathbb{V}[Y]}\)
\(S_3 \equiv \frac{V_3}{\mathbb{V}[Y]}\)
where the total variances \(\mathbb{V}[Y]\) is given in the section above and
the partial variances are given by:
\(V_1 = \frac{1}{2} \, (1 + \frac{b \pi^4}{5})^2\)
\(V_2 = \frac{a^2}{8}\)
\(V_3 = 0\)
The total-effect Sobol’ indices, on the other hand:
\(ST_1 \equiv \frac{VT_1}{\mathbb{V}[Y]}\)
\(ST_2 \equiv \frac{VT_2}{\mathbb{V}[Y]}\)
\(ST_3 \equiv \frac{VT_3}{\mathbb{V}[Y]}\)
where:
\(VT_1 = \frac{1}{2} \, (1 + \frac{b \pi^4}{5})^2 + \frac{8 b^2 \pi^8}{225}\)
\(VT_2 = \frac{a^2}{8}\)
\(VT_3 = \frac{8 b^2 \pi^8}{225}\)
Note, once more, that the values of the partial variances depend on the parameter values.
Note
The Ishigami function has a peculiar dependence on \(X_3\); the main-effect index of the input variable is \(0\) but the total-effect index is not, due to an interaction with \(X_1\)!
Furthermore, as can be seen from the function definition, \(X_2\) has no interaction effect; its main-effect and total-effect indices are exactly the same.
References#
T. Ishigami and T. Homma. An importance quantification technique in uncertainty analysis for computer models. In [1990] Proceedings. First International Symposium on Uncertainty Modeling and Analysis, 398–403. IEEE Comput. Soc. Press, 1991. doi:10.1109/ISUMA.1990.151285.
Ilya M. Sobol' and Yu L. Levitan. On the use of variance reducing multipliers in Monte Carlo computations of a global sensitivity index. Computer Physics Communications, 117(1):52–61, 1999. doi:10.1016/S0010-4655(98)00156-8.
Bruno Sudret. Global sensitivity analysis using polynomial chaos expansions. Reliability Engineering & System Safety, 93(7):964–979, 2008. doi:10.1016/j.ress.2007.04.002.
Amandine Marrel, Bertrand Iooss, Béatrice Laurent, and Olivier Roustant. Calculations of Sobol indices for the Gaussian process metamodel. Reliability Engineering & System Safety, 94(3):742–751, 2009. doi:10.1016/j.ress.2008.07.008.