Oakley and O’Hagan (2002) One-dimensional (1D) Function#
The 1D function from Oakley and O’Hagan (2002) (or Oakley1D function
for short) is a scalar-valued test function.
It was used in [OOHagan02] as a test function for illustrating metamodeling
and uncertainty propagation approaches.
import numpy as np
import matplotlib.pyplot as plt
import uqtestfuns as uqtf
A plot of the function is shown below for \(x \in [-12, 12]\).
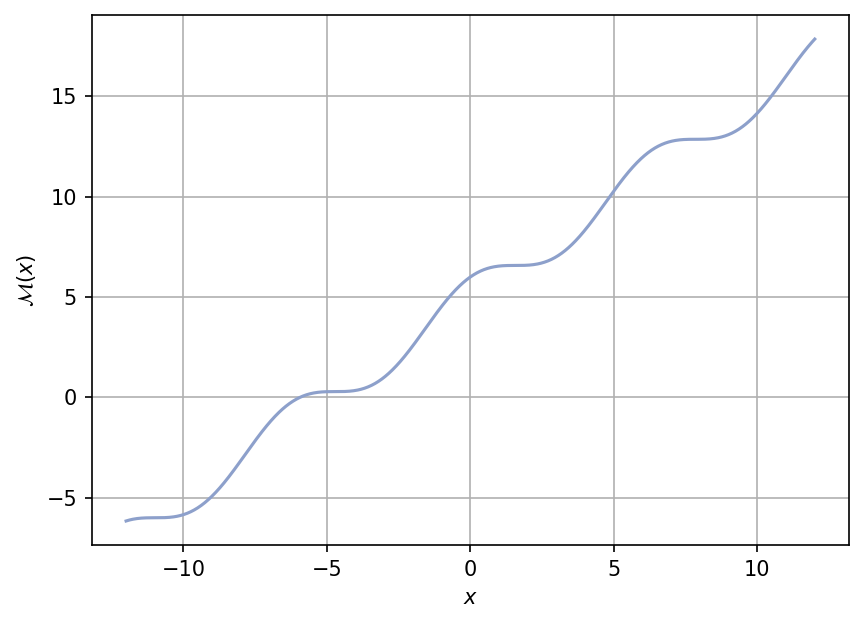
Test function instance#
To create a default instance of the test function:
my_testfun = uqtf.Oakley1D()
Check if it has been correctly instantiated:
print(my_testfun)
Function ID : Oakley1D
Input Dimension : 1 (fixed)
Output Dimension : 1
Parameterized : False
Description : One-dimensional function from Oakley and O'Hagan (2002)
Applications : metamodeling
Description#
The test function is analytically defined as follows:
where \(x\) is probabilistically defined below.
Probabilistic input#
Based on [OOHagan02], the probabilistic input model for the 1D Oakley-O’Hagan function consists of a normal random variable with the parameters shown in the table below.
Function ID : Oakley1D
Input ID : Oakley2002
Input Dimension : 1
Description : Probabilistic input model for the one-dimensional
function from Oakley and O'Hagan (2002)
Marginals :
No. Name Distribution Parameters Description
----- ------ -------------- ------------ -------------
1 x normal [0. 4.] -
Reference results#
This section provides several reference results of typical UQ analyses involving the test function.
Sample histogram#
Shown below is the histogram of the output based on \(100'000\) random points:
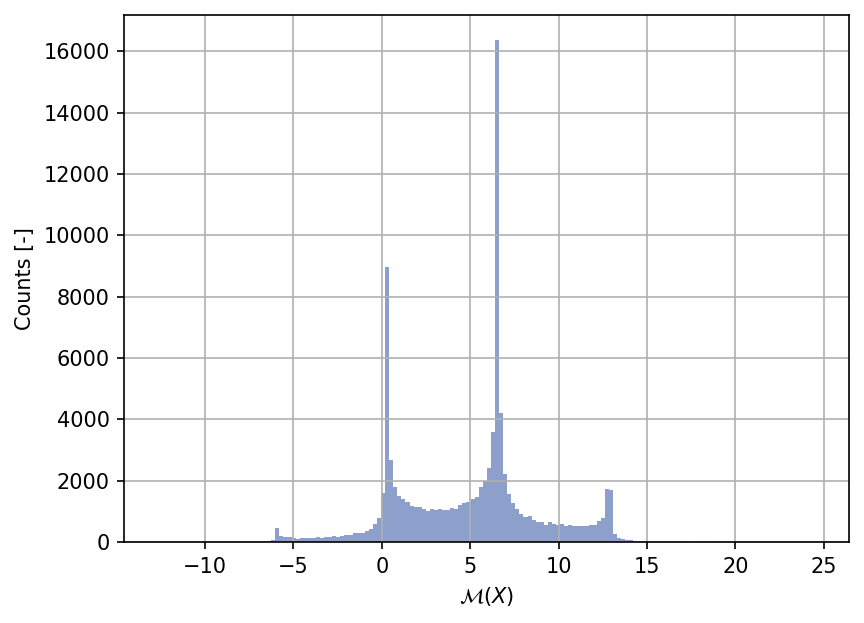
Moment estimations#
Shown below is the convergence of a direct Monte-Carlo estimation of the output mean and variance with increasing sample sizes.
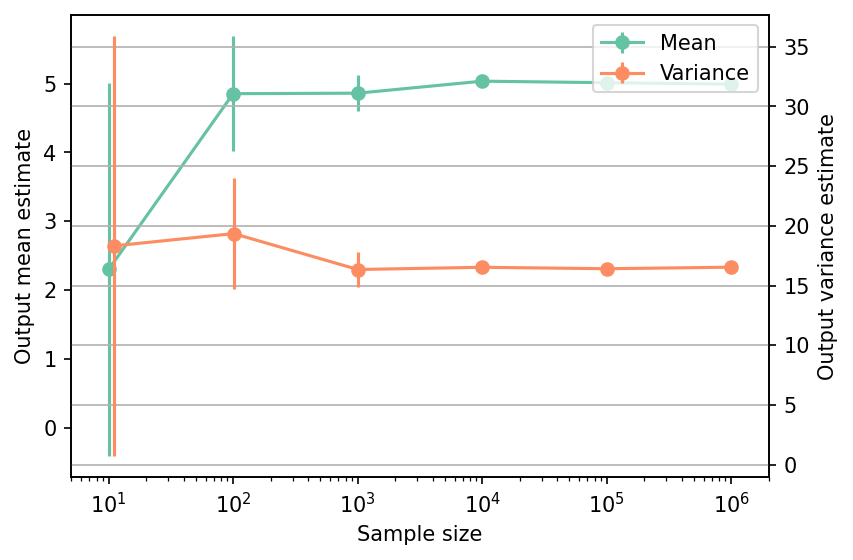
The tabulated results for each sample size is shown below.
| Sample size | Mean | Mean error | Variance | Variance error | Remark |
|---|---|---|---|---|---|
| 10 | 2.3003e+00 | 2.7088e+00 | 1.8323e+01 | 1.7948e+01 | Monte-Carlo |
| 100 | 4.8537e+00 | 8.3954e-01 | 1.9352e+01 | 4.7146e+00 | Monte-Carlo |
| 1000 | 4.8608e+00 | 2.6255e-01 | 1.6345e+01 | 1.4580e+00 | Monte-Carlo |
| 10000 | 5.0353e+00 | 8.3246e-02 | 1.6532e+01 | 3.7291e-01 | Monte-Carlo |
| 100000 | 5.0129e+00 | 2.4624e-02 | 1.6409e+01 | 1.4003e-01 | Monte-Carlo |
| 1000000 | 4.9926e+00 | 7.7767e-03 | 1.6539e+01 | 4.3497e-02 | Monte-Carlo |
References#
Jeremy Oakley and Anthony O'Hagan. Bayesian inference for the uncertainty distribution of computer model outputs. Biometrika, 89(4):769–784, 2002. doi:10.1093/biomet/89.4.769.